
Serverless
La computación sin servidor o Serverless es un concepto relativamente nuevo en la computación en la nube. Existe desde hace unos años, pero es ahora cuando está causando sensación en el mundo de las tecnologías de la información.
En Consultia hacemos un uso bastante extenso de este tipo de arquitectura. Es por esto que crearemos una serie de artículos al respecto, donde intentaremos explicar cómo funciona este modelo, y expondremos ejemplos prácticos para poder mostrar su potencial.
Pero antes de todo, ¿cómo que “sin servidor”?
¿Qué significa Serverless?
La computación sin servidor, o Serverless, es un modelo de ejecución en el que el proveedor de la nube (principalmente AWS, Azure o Google Cloud) se encarga de ejecutar una pieza de código asignando dinámicamente los recursos necesarios. Y solo cobra por la cantidad de recursos utilizados para ejecutar el código.
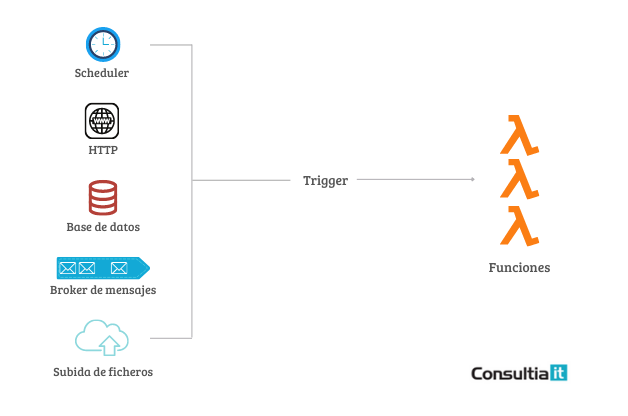
El código se ejecuta normalmente dentro de contenedores sin estado, que pueden ser activados por una variedad de eventos, incluyendo peticiones http, eventos de base de datos, servicios de colas de mensajería, alertas de monitorización, subidas de archivos, eventos programados (cron jobs), etc. El código que se envía al proveedor de la nube para su ejecución suele tener la forma de una función. Esto significa que los desarrolladores pueden crear aplicaciones sin tener que preocuparse por la gestión de la infraestructura subyacente, ni tampoco por cómo ese código va a ser ejecutado, ya que todo ello es administrado por el proveedor.
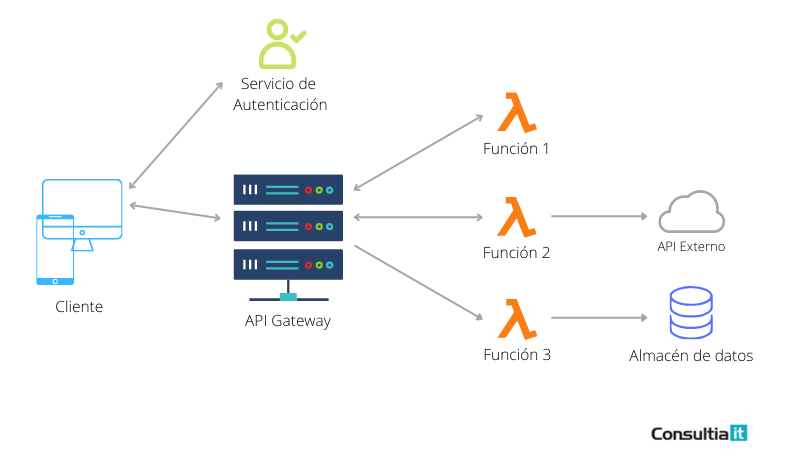
A diferencia de lo que ocurre con los servidores tradicionales (on-premise o en la nube), la computación sin servidor permite al desarrollador centrarse simplemente en su código y no tener que preocuparse por el aprovisionamiento de servidores ni por su mantenimiento una vez que están en producción, sin preocuparse si el servidor está disponible 24/7 o tiene actualizada la última versión del sistema operativo.
¿Significa esto que las aplicaciones son capaces de ejecutarse sin un servidor?
No exactamente. En este contexto, el término “sin servidor” se refiere al hecho de que cuando se despliega la aplicación, ésta se carga en una máquina en algún lugar, pero no es necesario pensar en cómo se ejecutará: ¡sólo hay que escribir el código! La infraestructura es gestionada, al menos parcialmente, por un proveedor de servicios externo, lo que significa que es éste el que se encarga de aumentar o disminuir la escala en función de la demanda, garantizando la escalabilidad, el mantenimiento, la ejecución y la disponibilidad de los servicios en todo momento.
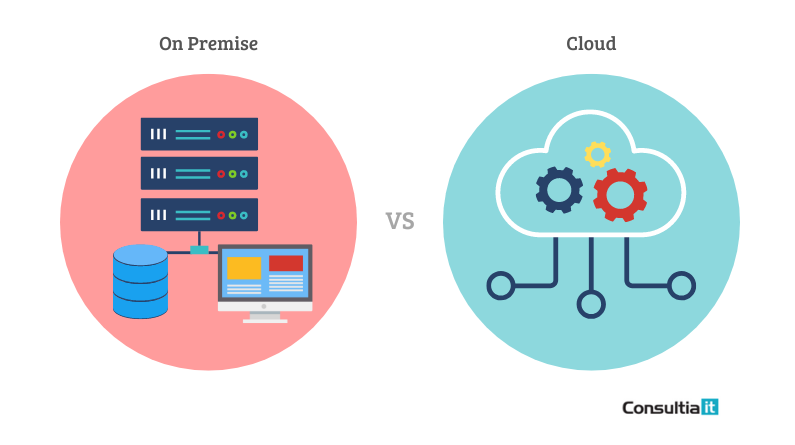
Anteriormente, si estabas construyendo un servicio o sitio web que requiere un backend, es decir, un sitio no estático, sólo había dos opciones entre las que elegir:
-
Configurar y desplegar un servidor propio y operarlo tú mismo. Se utilizan servidores dedicados internos, se requiere de inversión inicial considerable, donde se deben comprar los equipos técnicos, concesión de licencias de software y la contratación de un equipo de mantenimiento.
-
Utilizar los servidores de un proveedor cloud y pasar por una API para comunicarte con él. La infraestructura pertenece al proveedor, el cliente paga de forma mensual. No hace falta una inversión en un equipo técnico ya que el proveedor se encarga, pero sí es necesaria la administración y el mantenimiento de la infraestructura.
En el modelo Serverless, el proveedor de la nube gestiona completamente el sistema operativo, el almacenamiento y la infraestructura de red que ejecuta la aplicación. Se diferencia de otras formas de computación en nube en que no utiliza máquinas virtuales (VM), sino contenedores o funciones.
Aunque la computación sin servidor no es un concepto nuevo, recientemente esta tecnología ha visto un aumento en el interés. Según las encuestas de StackOverflow, las tecnologías sin servidor se han elevado hasta convertirse en uno de los modelos de desarrollo de software más populares en la actualidad.
¿Cuáles son sus ventajas?
A medida que el software se ha ido pasando al modelo de la nube, se iban detectando dos principales inconvenientes:
-
Inactividad: Se paga por todo lo que se usa, por lo que las aplicaciones pagaban por el 100% del tiempo, pero sólo se usaban un % reducido del tiempo.
-
Gestión: Incluso con el servidor funcionando en algún lugar “mágico”, seguía siendo necesario un equipo para instalar parches y actualizaciones, además de pruebas de regresión en cada actualización de versión. Al final, se sigue teniendo un servidor on-premise pero fuera del centro de datos propio, atendido por otro equipo externo.
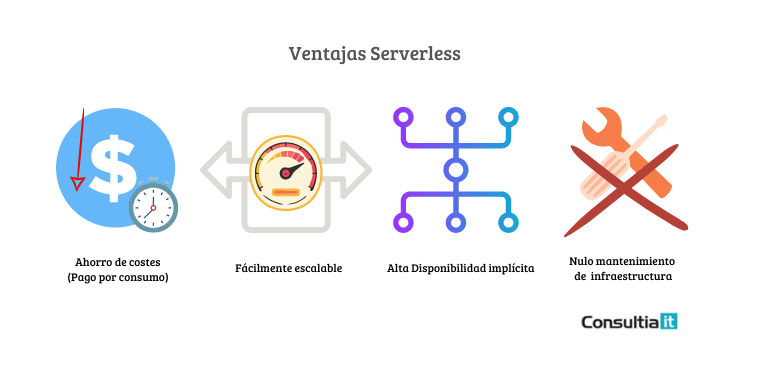
Estos problemas hicieron posible el impulso de la computación sin servidor, que ofrece varias ventajas, entre ellas:
-
Ahorro de costes: Las arquitecturas sin servidor proporcionan un importante ahorro de costes, especialmente para las pequeñas y medianas empresas. El coste de una arquitectura sin servidor se basa en el consumo de recursos, y es muy fácil ampliar o reducir su aplicación según sea necesario sin ningún esfuerzo. De hecho, se puede incluso ahorrar dinero utilizando la arquitectura sin servidor porque elimina la necesidad de gestionar la infraestructura.
-
Mejor rendimiento: Las arquitecturas sin servidor son altamente escalables, y proporcionan un mejor rendimiento ya que están optimizadas para la velocidad, no para la eficiencia. Esto significa que una aplicación responderá mucho más rápido que si se utilizaran soluciones de alojamiento gestionadas tradicionales, como máquinas virtuales o contenedores.
-
Flexibilidad: Las arquitecturas sin servidor son muy flexibles porque puedes elegir exactamente cuándo y cuánta potencia de cálculo necesita tu aplicación en cada momento. También puede cambiar la cantidad de potencia de cálculo necesaria sin afectar a otras partes de su aplicación o a sus usuarios, ya que cada función se ejecuta de forma aislada de todas las demás.
-
Fiable: Las arquitecturas sin servidor se construyen sobre servicios de terceros proveedores que se encargan de la disponibilidad y la fiabilidad por ti.
-
Reducción de la latencia: Con Serverless, no es necesario alojar una aplicación en un servidor de origen, ya que el código de la aplicación puede ejecutarse desde cualquier lugar. La mayoría de los proveedores de la nube despliegan el código en varios servidores y permiten que se ejecute en los servidores que están cerca del usuario final. Esto reduce la latencia, ya que las peticiones del usuario se ejecutan simplemente desde el servidor más cercano.
Principales proveedores
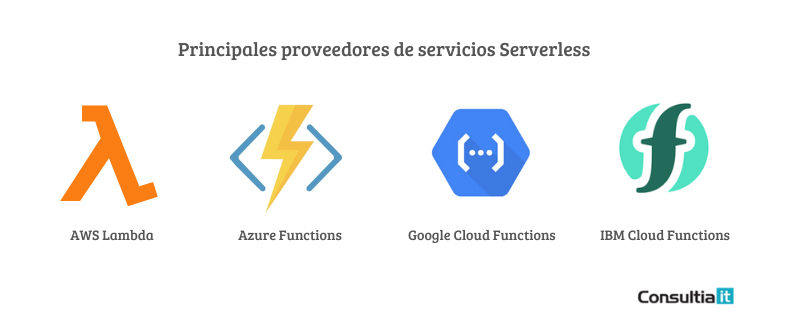
Existen varios proveedores de servicios Serverless en el panorama actual, de los cuales Lambda de Amazon Web Services (AWS) es actualmente el más conocido.
A continuación, se muestran los más importantes:
- AWS Lambda, de Amazon
- Azure Functions, de Microsoft
- GCP Cloud Functions, de Google
- IBM Cloud Functions, de IBM
Cada uno de ellos tiene sus particularidades. Tienen distintas limitaciones, soportan distintos lenguajes de programación y tienen distintos modelos de precio.
En esta serie de artículos sobre servicios Serverless, nos centraremos sobre el ecosistema de productos de Amazon AWS.
Casos de uso reales
Activadores de eventos (Event triggers)
Serverless es ideal para cualquier actividad que desencadene un evento o una serie de eventos, como la captura de cambios en los datos. Un cambio en una base de datos puede desencadenar una tarea de replicación para garantizar la actualización de una base de datos de respaldo.
Procesamiento asíncrono
Las funciones sin servidor pueden encargarse de diversas tareas de la aplicación “en backgroud”, como por ejemplo la generación de varios tamaños de una imagen o la transcripción de vídeos después de su carga. Lo hace sin añadir ninguna latencia de cara al usuario, porque la tarea continúa sin interrumpir el flujo de la aplicación.
Integración continua/despliegue continuo
Los pipelines de integración continua/despliegue continuo (CI/CD) permiten enviar el código en pequeños incrementos para permitir la rápida corrección de errores y actualizaciones. Serverless puede automatizar estos procesos. Por ejemplo:
-
Cuando se realizan cambios en el código, se puede activar una función sin servidor para crear una compilación.
-
Cuando se crea un pull request en un repositorio GIT, una función sin servidor puede ser activada para iniciar las pruebas automatizadas.
Aplicaciones políglotas
Serverless permite construir aplicaciones políglotas, lo que significa que se pueden utilizar varios lenguajes de programación y construir cada función en el lenguaje más apropiado. Esto evita que el equipo de desarrollo quede “atado” a un lenguaje heredado, ya que se pueden utilizar nuevos lenguajes para construir nuevas funciones.
