Extracción de datos en CSV de S3 a Amazon DynamoDB usando AWS Lambda
El objetivo de esta prueba de concepto es ver cómo integrar 3 de los servicios más utilizados de todo el ecosistema AWS:
- Amazon S3
- AWS Lambda
- Amazon DynamoDB
Con ellos, implementaremos una solución para cargar datos en una base de datos de manera automática a partir de ficheros CSV.
- Arquitectura de la solución
- Caso de uso
- Prerrequisitos
- Creación del bucket en S3
- Creación de la función Lambda
- Creación de la tabla de datos DynamoDB
- Implementación de la función Lambda
- Generación del JAR ejecutable
- Carga de código en la función AWS Lambda
- Pruebas
- Recursos
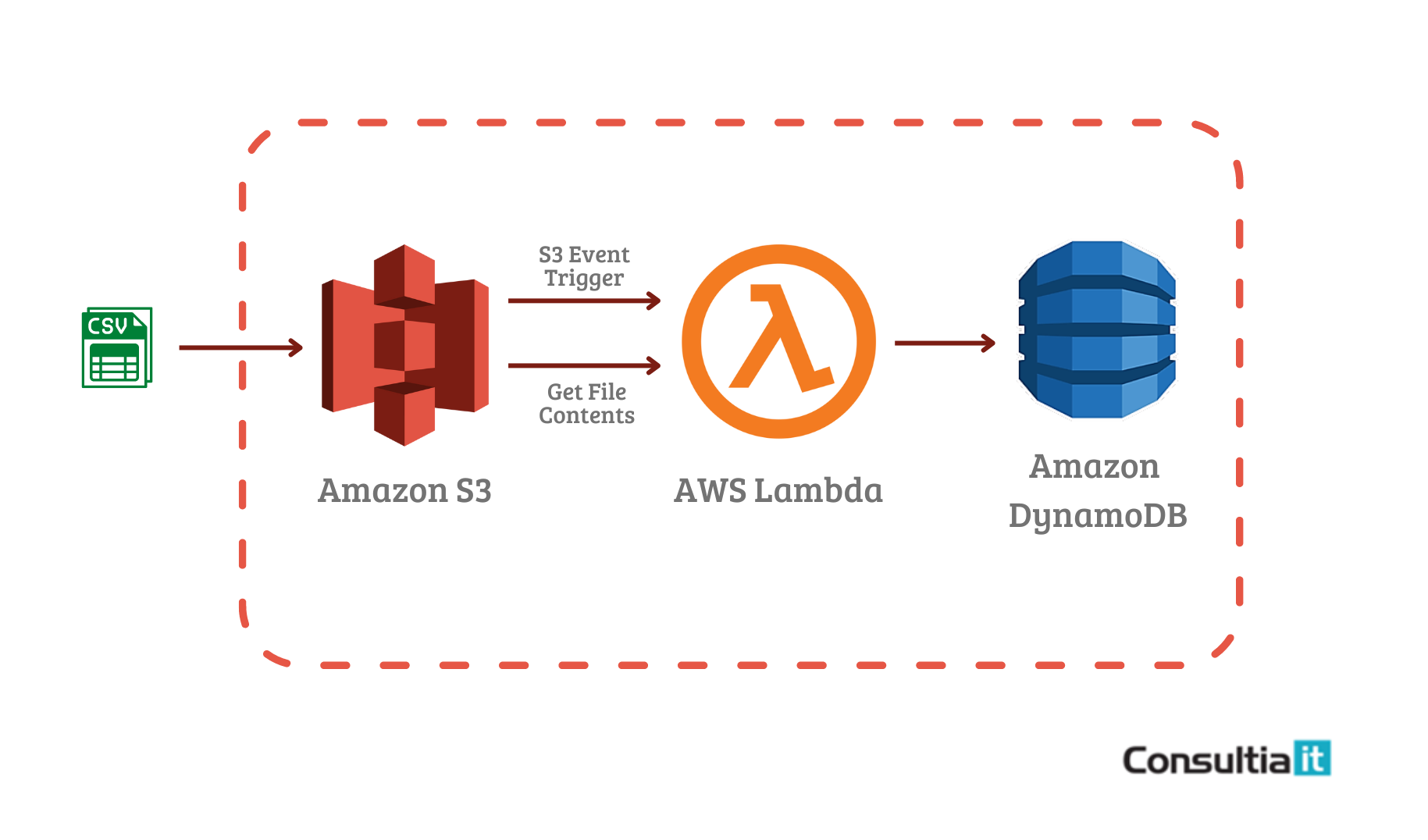
Arquitectura de la solución
La arquitectura de la solución, como comentábamos anteriormente, pasa por la integración de los 3 servicios de AWS implicados.
Caso de uso
Imaginemos que estamos en una organización donde los datos de sus empleados están en un sistema que permite exportarlos en formato CSV, y queremos cargar esos datos en una base de datos para su explotación.
Suponiendo que queremos una solución sencilla, fácil de mantener y limitada a archivos pequeños/medianos, la función AWS Lambda encaja perfectamente en esta situación.
La idea es muy sencilla. Los ficheros .csv serán cargados en un bucket de Amazon S3, lo que disparará un evento que activará una función Lambda, cuyo objetivo es parsear los documentos recién subidos, extraer la información e insertar los datos en una base de datos DynamoDB.
Para llevarlo a cabo, vamos a tener que realizar una serie de acciones que se pueden resumir en 3 pasos:
- Cargar el fichero CSV en un bucket de Amazon S3, a través de la consola AWS
- Parsear los ficheros entrantes en el bucket, para extraer los datos y organizarlos en base a la estructura que nos interesa, en una función Lambda
- Guardar los datos en una base de datos Amazon DynamoDB
Los datos que contienen la información de los empleados tienen la siguiente estructura:
| Campo | Tipo |
|---|---|
| ID de empleado | Numérico |
| Nombre | String |
| Salario | Double |
Un ejemplo podría ser el siguiente fichero (empleados.csv):
1,"Pedro",30000
2,"Juan",35000
Prerrequisitos
- SDK Java 11
- Maven
- Cuenta en Amazon Web Services (AWS). Los primeros 12 meses son gratuitos, y el servicio S3 proporciona hasta 5 TB de almacenamiento gratuito.
- Tu IDE favorito. En este caso, Spring Tool Suite (STS), con el plugin AWS Toolkit for Eclipse.
Creación del bucket en S3
Lo primero que vamos a hacer es crear un bucket en Amazon S3 a través de la consola de AWS. Como comentamos siempre, lo mejor es seguir la propia documentación del servicio, que siempre está actualizada: https://aws.amazon.com/es/getting-started/hands-on/backup-files-to-amazon-s3/
En este caso, vamos a crear un bucket con el nombre input-csv-employees-data, seleccionando la región que aplique según nuestra localización y dejando por defecto el resto de configuración:
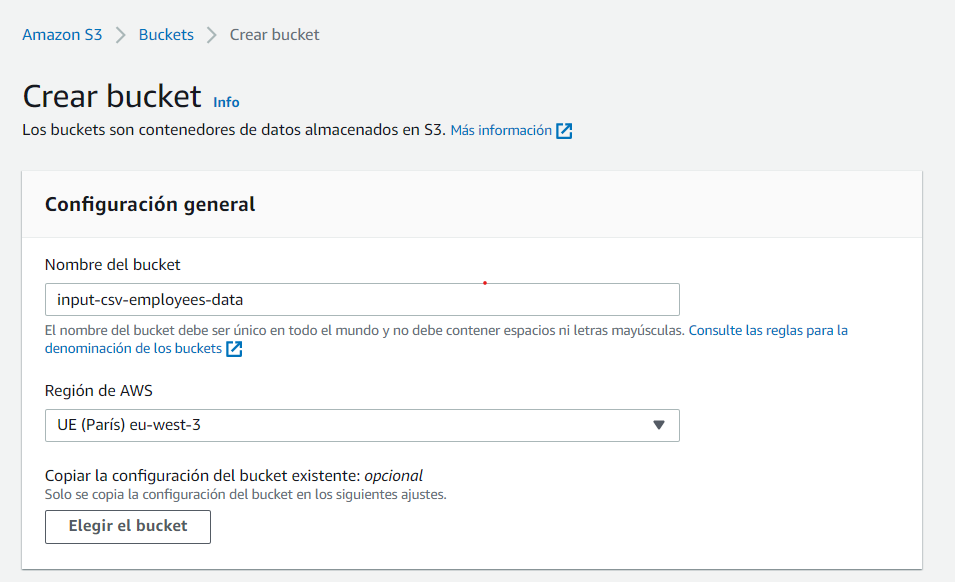
Recuerda que el nombre del bucket debe ser único en todo AWS, no sólo en la cuenta usada.
Creación de la función Lambda
Accede al servicio Lambda y crea una nueva función:
Darle un nombre a la función (en este ejemplo “parseEmployeeCsv”), seleccionar el tiempo de ejecución “Java 11” y en la sección de permisos, “Creación de un nuevo rol desde la política de AWS templates”. Aquí, haciendo uso del buscador, seleccionar las siguientes políticas:
- Permisos de microservicios sencillos (DynamoDB)
- Permisos de solo lectura de objetos de Amazon S3
Le damos un nombre al nuevo rol (en este ejemplo “myCsvParserRole”) y pulsamos en “Crear una función”
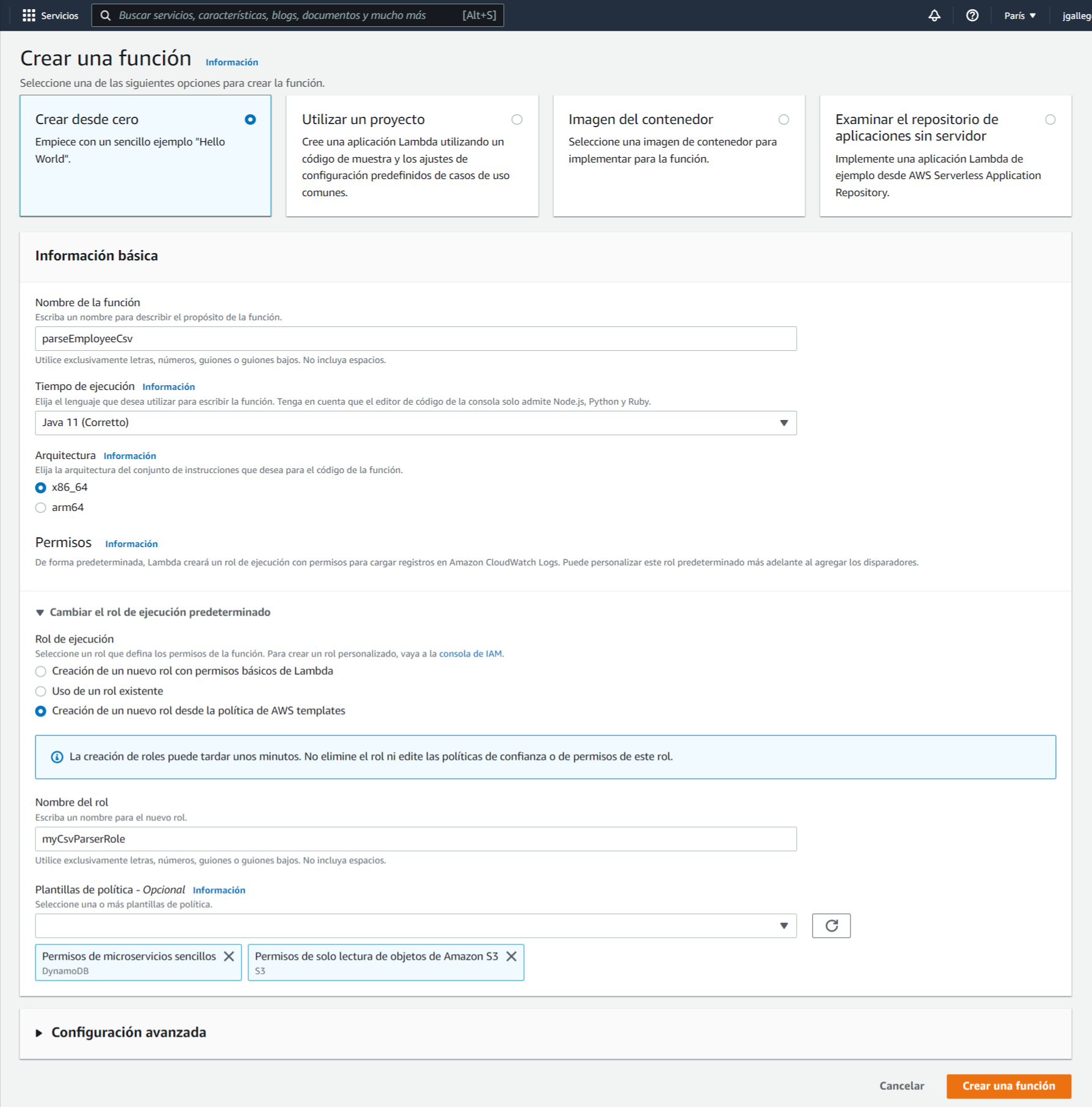
Esto nos lleva al detalle de la recién creada función Lambda:
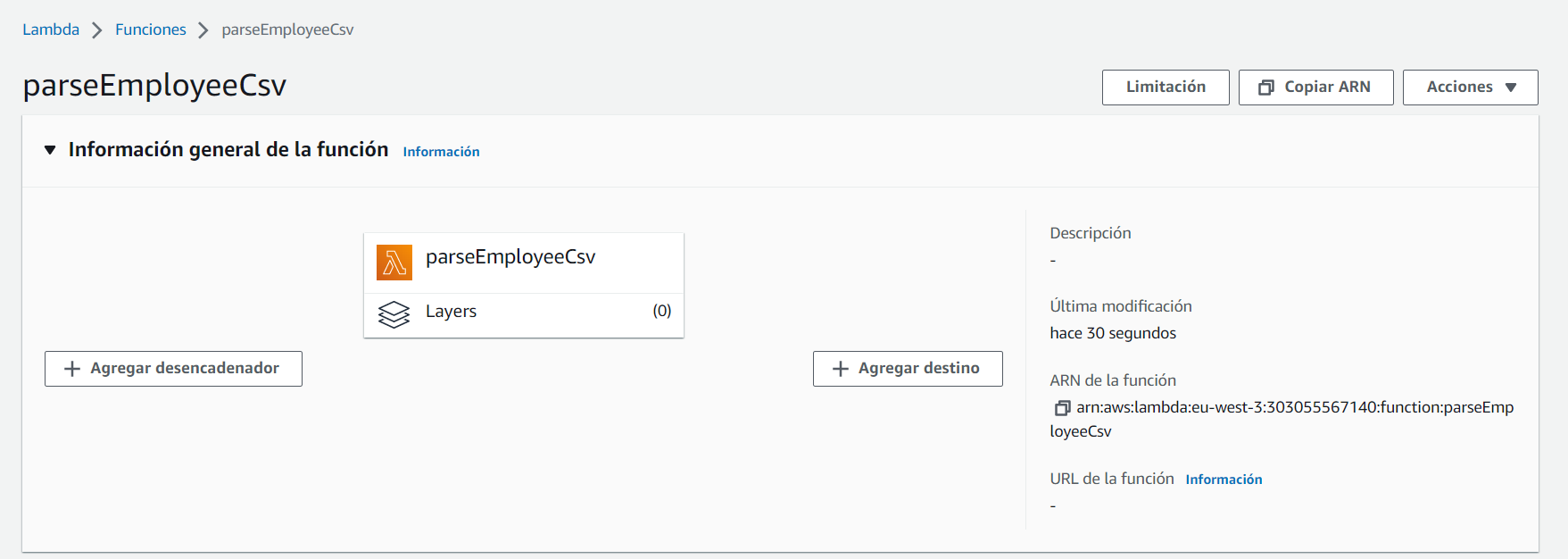
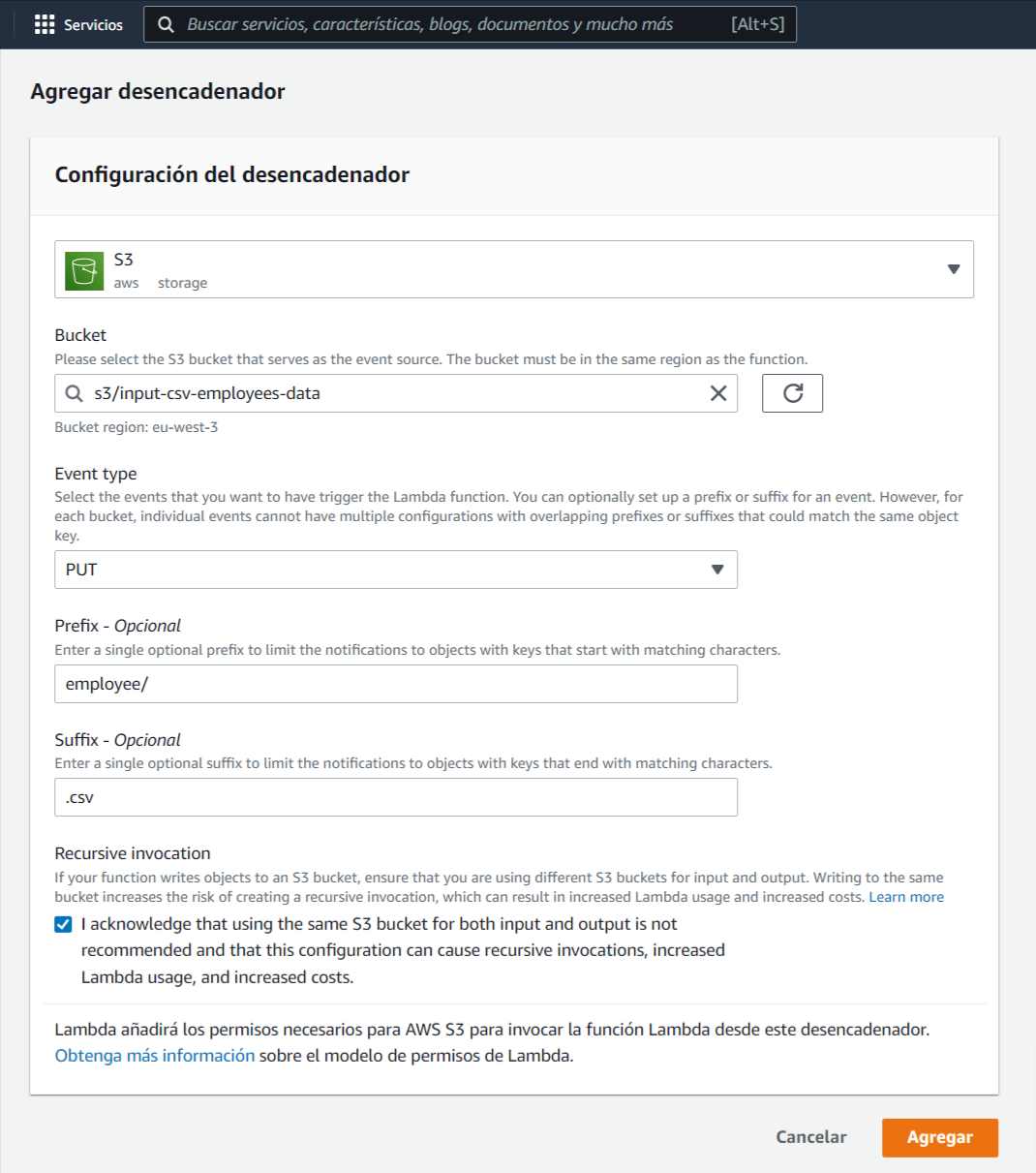
El siguiente paso es agregar un desencadenador, pulsando en el botón “Agregar desencadenador”. En este nuevo formulario, configuramos lo siguiente:
- seleccionamos como origen el servicio S3
- indicamos el bucket donde depositaremos los .csv de empleados
- seleccionamos el tipo de evento que servirá como disparador de la función lambda. En este caso PUT, que se corresponde con el evento de carga/actualización de un fichero .csv en el bucket
- añadimos un prefijo, que servirá como carpeta, donde depositaremos los ficheros .csv. Esto no es necesario, pero lo haremos así por temas de organización, ya que en el bucket pueden existir distintos tipos de archivos
- añadimos como sufijo la extensión de los ficheros que queremos que disparen la notificación del desencadenador. En este caso, sólo queremos que nuestra función Lambda parsee los ficheros .csv
Esto nos lleva de nuevo al detalle de la función Lambda, donde podemos observar que existe el desencadenador recién creado asociado a la función:
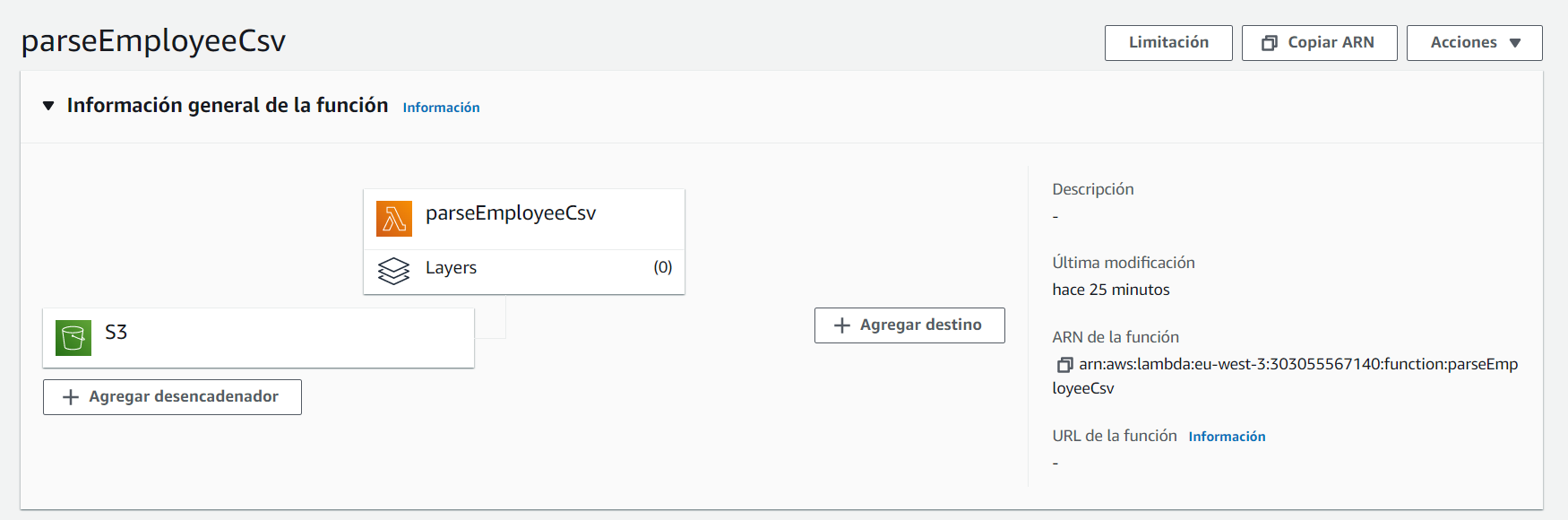
Creación de la tabla de datos DynamoDB
Acceder al servicio DynamoDB y crear una nueva tabla:
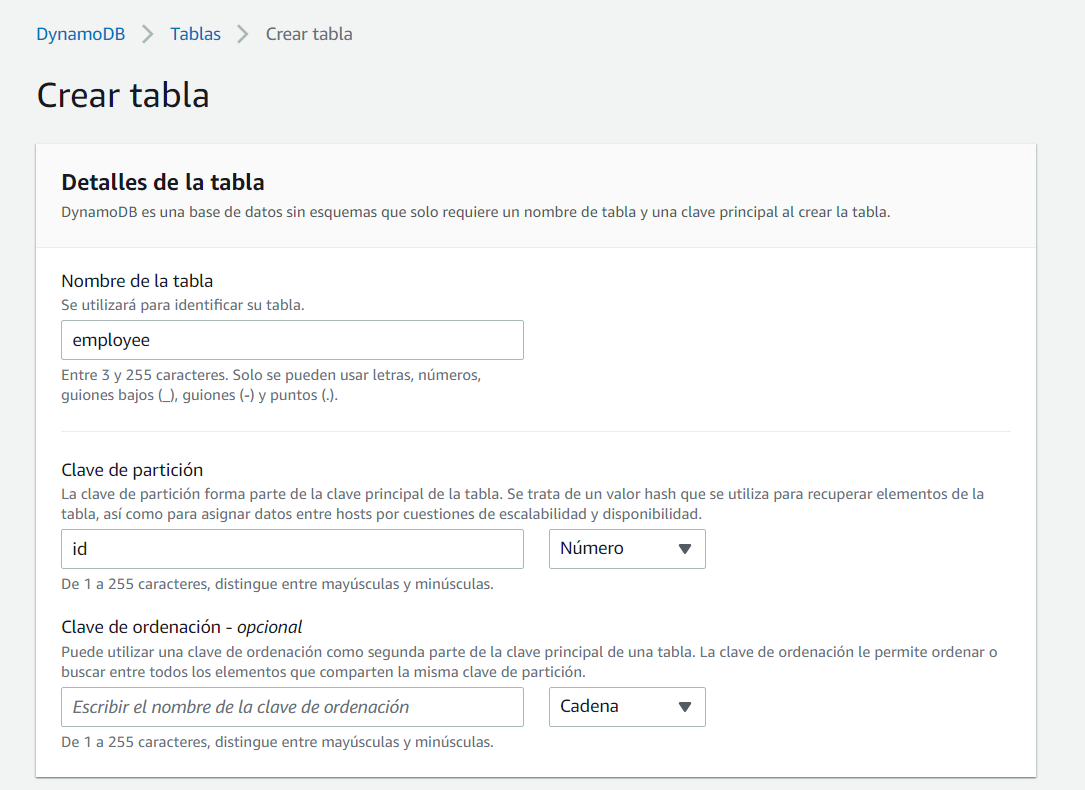
Damos un nombre a la nueva tabla, en este caso “employee”, y como “Clave de partición” escribimos “id”, que se corresponderá con el campo Id de empleado, de tipo numérico:
Implementación de la función Lambda
Para la implementación de la función Lamda, vamos a crear un nuevo proyecto Maven, con Java 11.
Para ello, vamos a hacer uso del plugin AWS Toolkit for Eclipse.
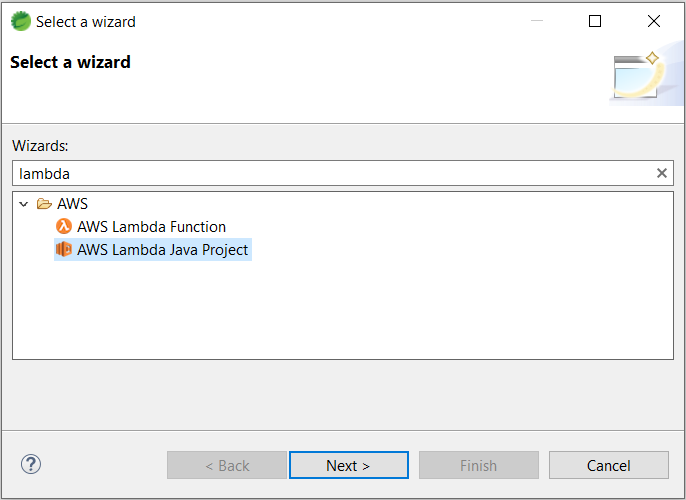
Creamos un nuevo proyecto, seleccionando el wizard “AWS Lambda Lambda Project”:
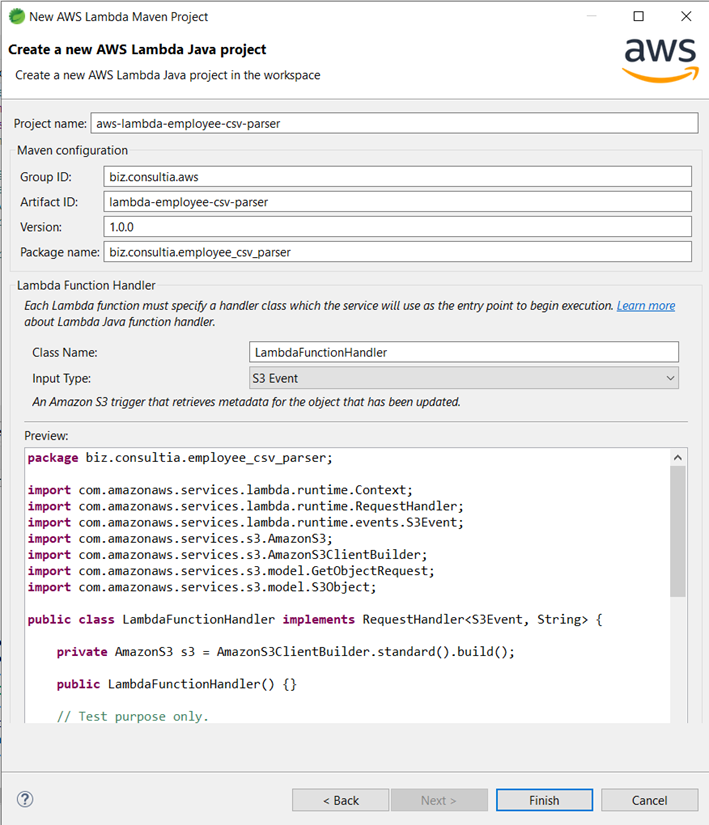
Completamos los datos de configuración de Maven, y seleccionamos el tipo de evento que funcionará como disparador de la función lambda que vamos a implementar en este proyecto. En este caso, S3 Event:
Una vez generado el proyecto, vemos que sólo tiene una única clase, LambdaFuncionHandler, con un solo método, handleRequest, que es el que debemos implementar.
Veamos un poco el código de la función:
public class LambdaFunctionHandler implements RequestHandler<S3Event, String> {
/** The DynamoDB table name. */
String DYNAMO_TABLE_NAME = "employee";
private AmazonS3 s3 = AmazonS3ClientBuilder.standard().build();
private AmazonDynamoDB dynamoDBClient = AmazonDynamoDBClientBuilder.standard().withRegion(Regions.EU_WEST_3).build();
@Override
public String handleRequest(S3Event event, Context context) {
context.getLogger().log("Received event: " + event);
// 1. Get the bucket name and its object key from the S3 event
String bucket = event.getRecords().get(0).getS3().getBucket().getName();
String key = event.getRecords().get(0).getS3().getObject().getKey();
S3Object response = null;
String contentType;
try {
// 2. Get the object from Amazon S3
response = s3.getObject(new GetObjectRequest(bucket, key));
contentType = response.getObjectMetadata().getContentType();
context.getLogger().log("CONTENT TYPE: " + contentType);
}
catch (Exception e) {
e.printStackTrace();
context.getLogger().log(String.format(
"Error getting object %s from bucket %s. Make sure they exist and your bucket is in the same region as this function.", key, bucket));
throw e;
}
// 3. Parse the S3 object content
List<String[]> rows = parseCSVS3Object(response);
// 4. Insert each element into the DynamoDB table
rows.forEach(row -> {
putItemInTable(row[0], row[1], row[2]);
});
return contentType;
}
private List<String[]> parseCSVS3Object(S3Object data) {
BufferedReader reader = new BufferedReader(new InputStreamReader(data.getObjectContent()));
try {
String line;
List<String[]> rows = new ArrayList<>();
while ((line = reader.readLine()) != null) {
rows.add(line.split(","));
}
return rows;
}
catch (IOException e) {
throw new RuntimeException(e);
}
}
public void putItemInTable(String employeeId, String employeeName, String employeeSalary) {
HashMap<String, AttributeValue> itemValues = new HashMap<>();
itemValues.put("id", new AttributeValue().withN(employeeId));
itemValues.put("name", new AttributeValue(employeeName));
itemValues.put("salary", new AttributeValue().withN(employeeSalary));
PutItemRequest request = new PutItemRequest(DYNAMO_TABLE_NAME, itemValues);
try {
dynamoDBClient.putItem(request);
System.out.println(DYNAMO_TABLE_NAME + " was successfully updated");
}
catch (ResourceNotFoundException e) {
System.err.format("Error: The Amazon DynamoDB table \"%s\" can't be found.\n", DYNAMO_TABLE_NAME);
System.err.println("Be sure that it exists and that you've typed its name correctly!");
System.exit(1);
}
catch (AmazonDynamoDBException e) {
System.err.println(e.getMessage());
System.exit(1);
}
}
}
Básicamente, el algoritmo es el siguiente:
- El manejador del evento recibe un evento de tipo S3Event, del que obtenemos el bucket donde se ha depositado el nuevo .csv y el key que identifica al fichero.
- Con esos dos datos, y haciendo uso del cliente S3 que proporciona el SDK de AWS, accedemos al objeto que representa al fichero
- Una vez que tenemos el contenido del fichero .csv, procedemos a parsearlo, línea a línea
- Para cada uno de los registros, y haciendo uso del cliente DynamoDB que proporciona el SDK de AWS, insertamos un nuevo elemento con los tres datos que disponemos de los empleados que figuran en el .csv.
Generación del JAR ejecutable
Para crear un paquete de implementación con Maven, vamos a usar el plugin Maven Shade. Este plugin complemento crea un archivo JAR que contiene el código compilado de la función y todas sus dependencias.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.0</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
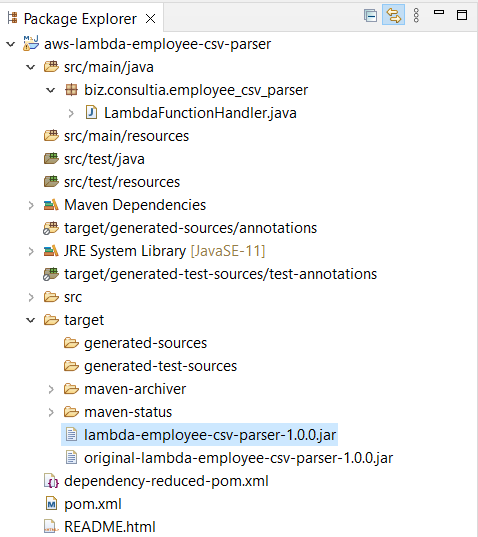
Para crear el paquete de implementación, basta con ejecutar el comando mvn package, que nos generará el archivo JAR en el directorio target del proyecto:
Carga de código en la función AWS Lambda
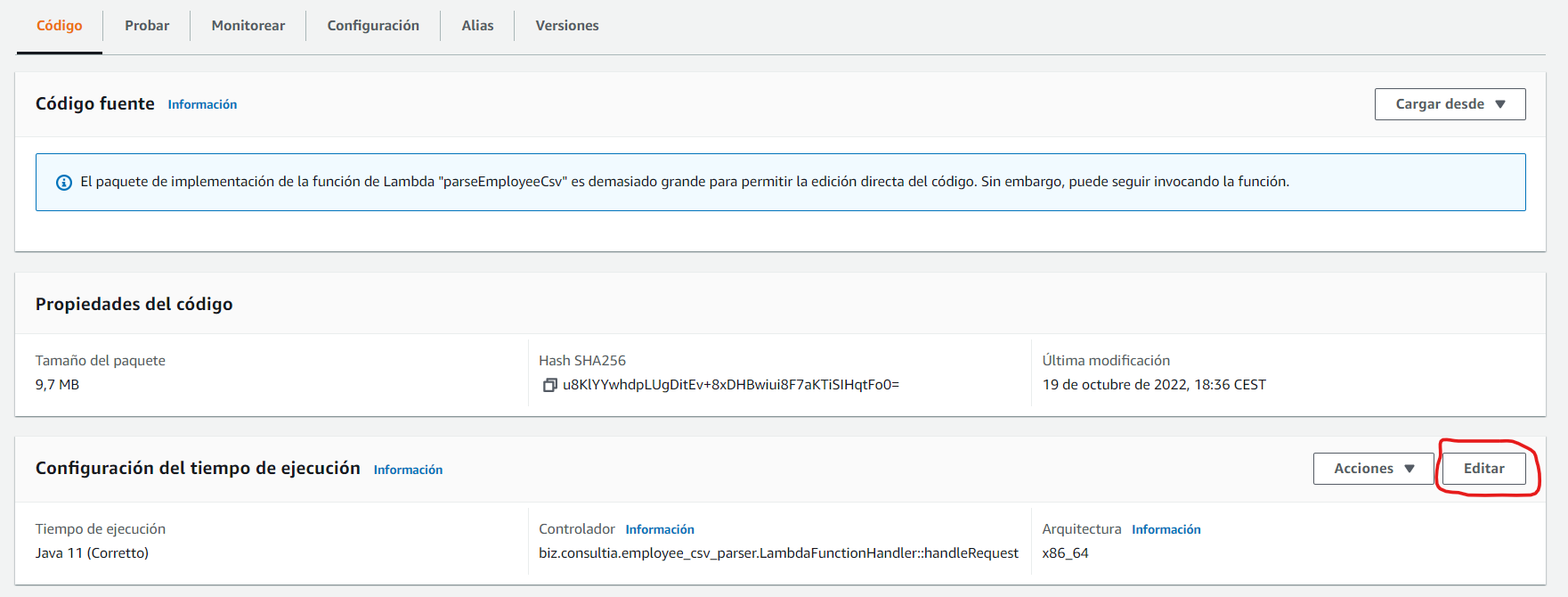
Una vez que tenemos el .jar de la implementación de la función, es el turno de cargarla en la función AWS Lambda. Para ello, desde el detalle de la función, bajo la pestaña “Codigo”, cargamos el código como archivo .zip o .jar.

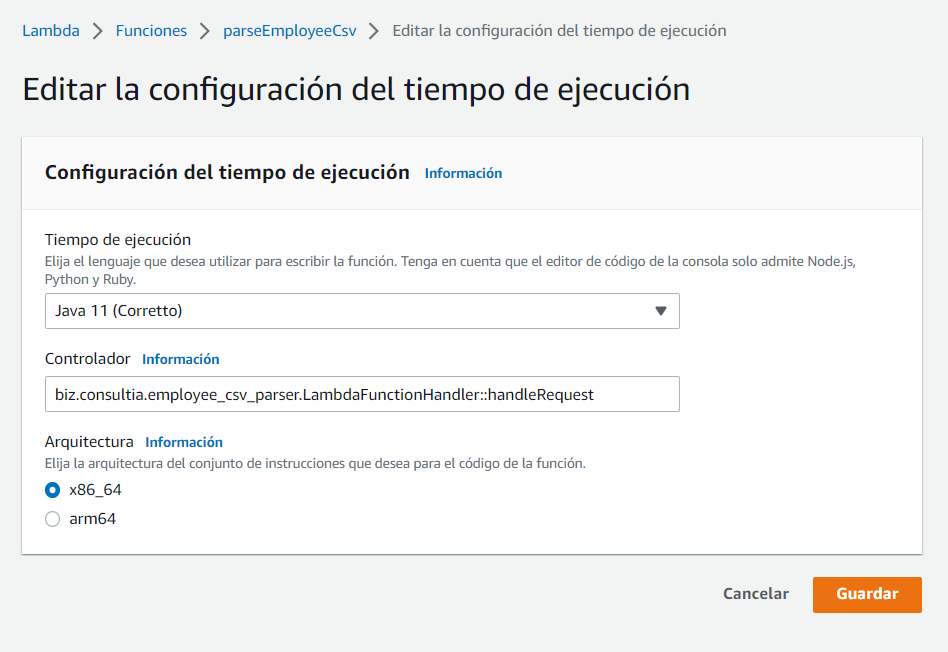
Por último, debemos configurar el controlador de la función Lambda. Para ello, una vez cargado el código, y bajo la misma pestaña, accedemos a la edición de la “Configuración del tiempo de ejecución”:
En el campo “Controlador”, insertamos el nombre completo del método que implementa el manejo de la petición:
Y listo. Ya esta todo completamente configurado y funcional.
Pruebas
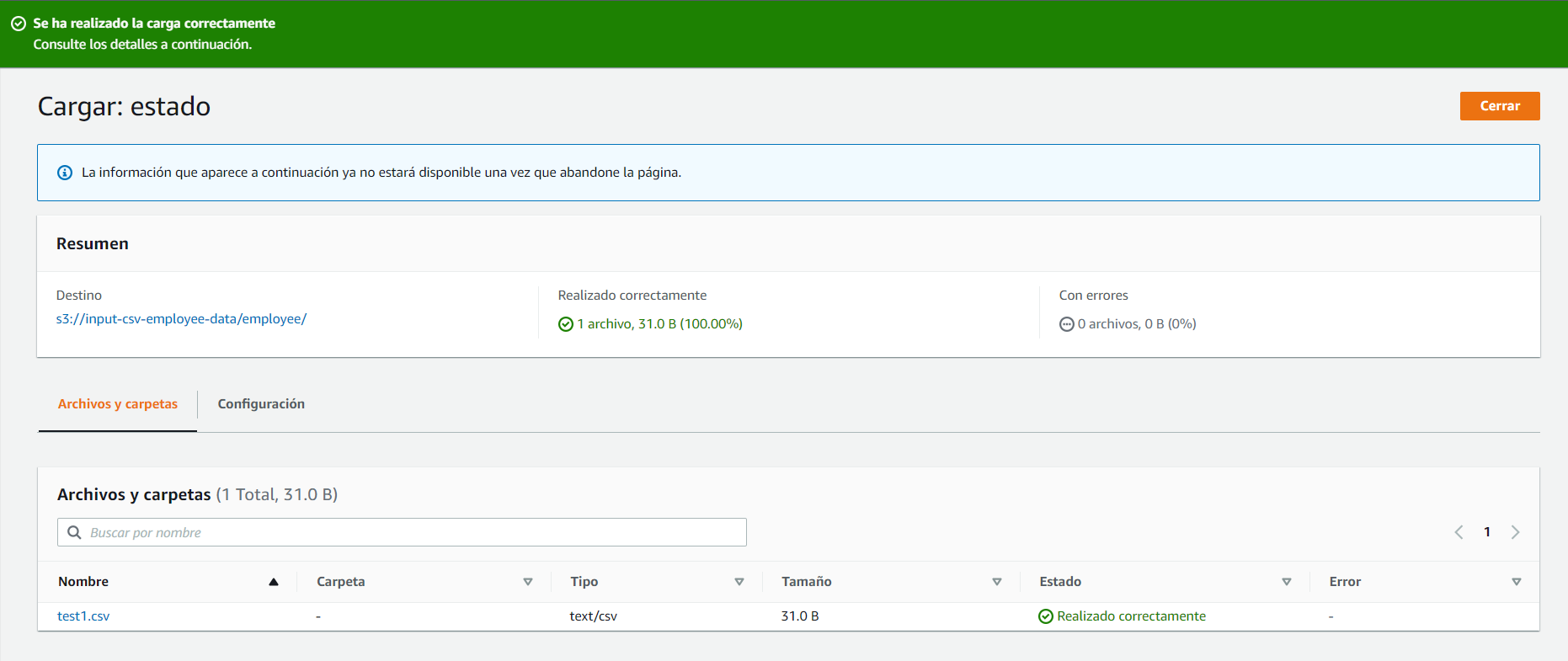
Ahora ya sí, podemos cargar un fichero .csv en la carpeta /employee del bucket creado anteriormente, a través de la consola AWS:
Desde el detalle de la función Lambda, en la pestaña “Monitorear”, podemos acceder a los logs registrados en CloudWatch:
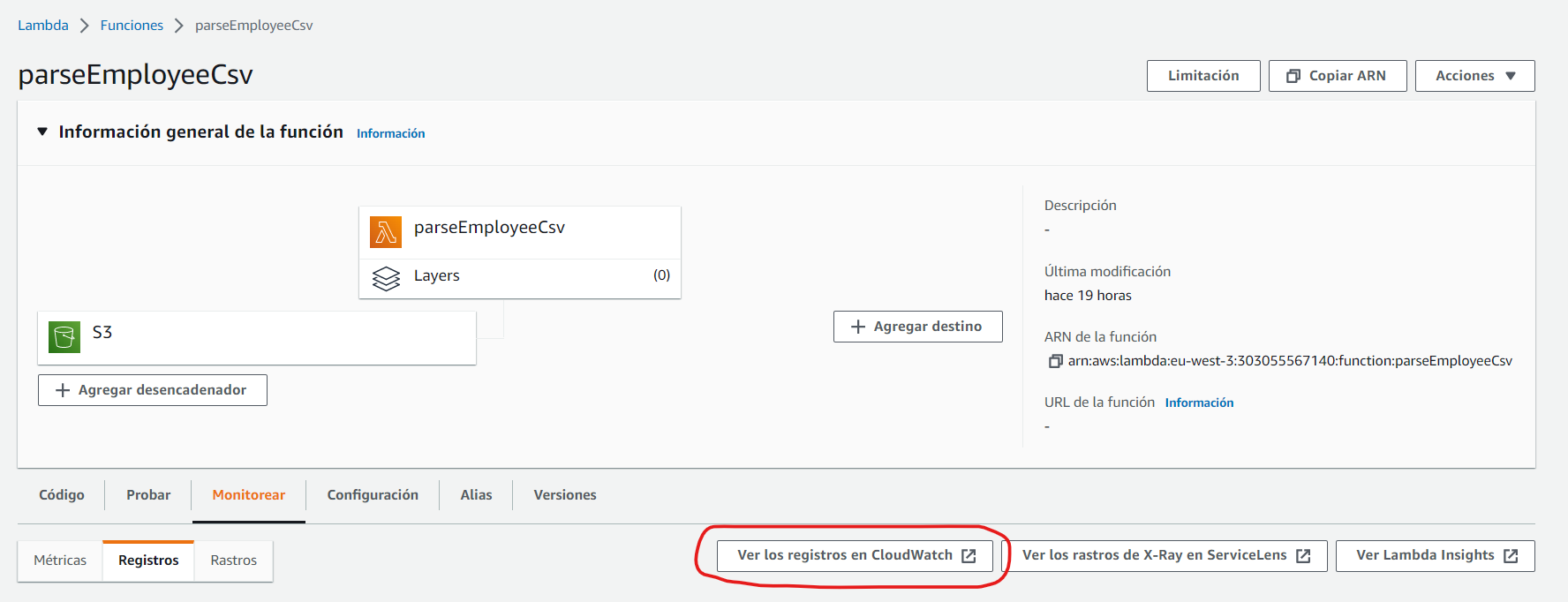
Donde podemos ver que se ha generado un registro:
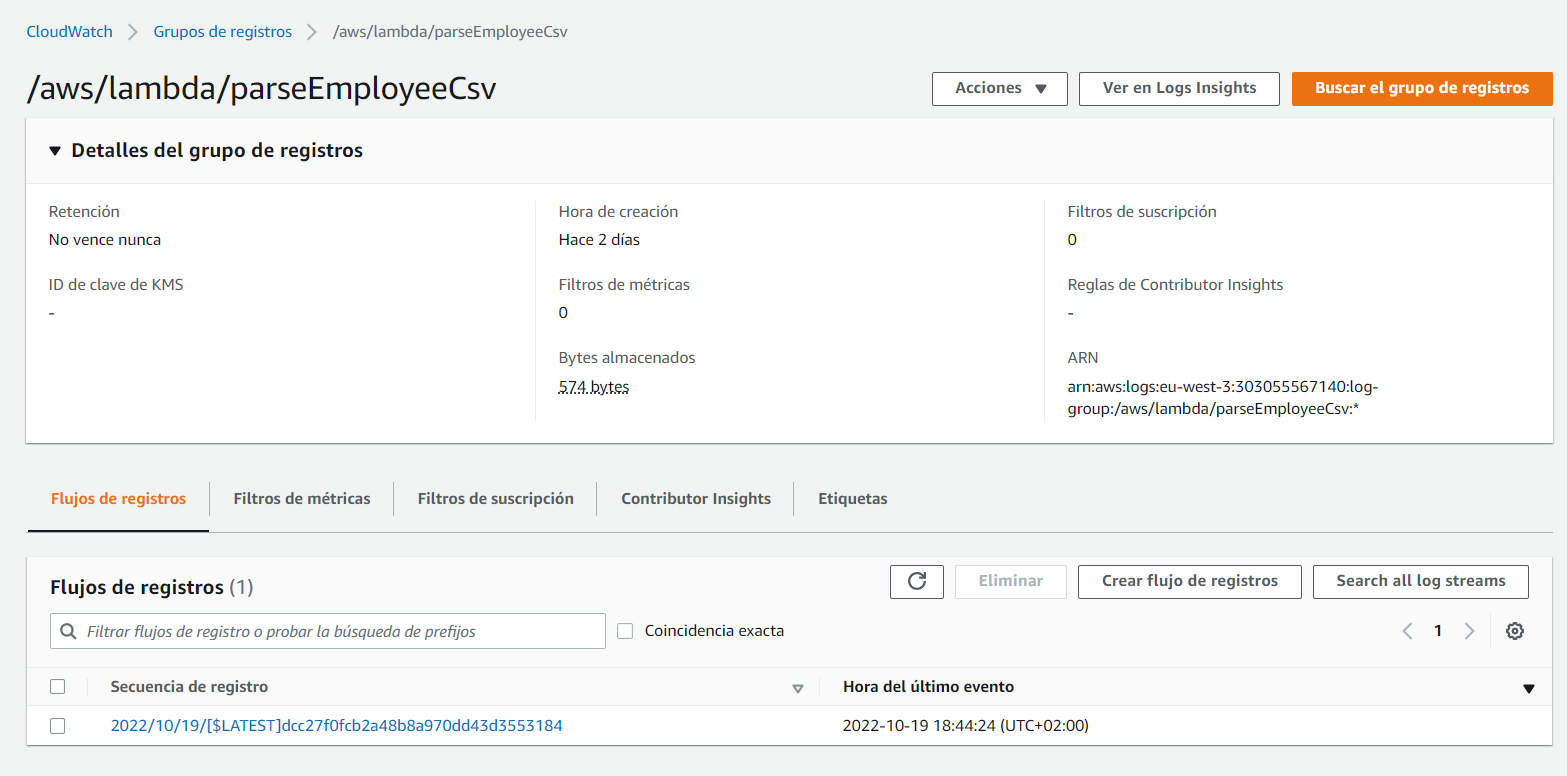
En las trazas, podemos comprobar que todo ha ido correctamente:
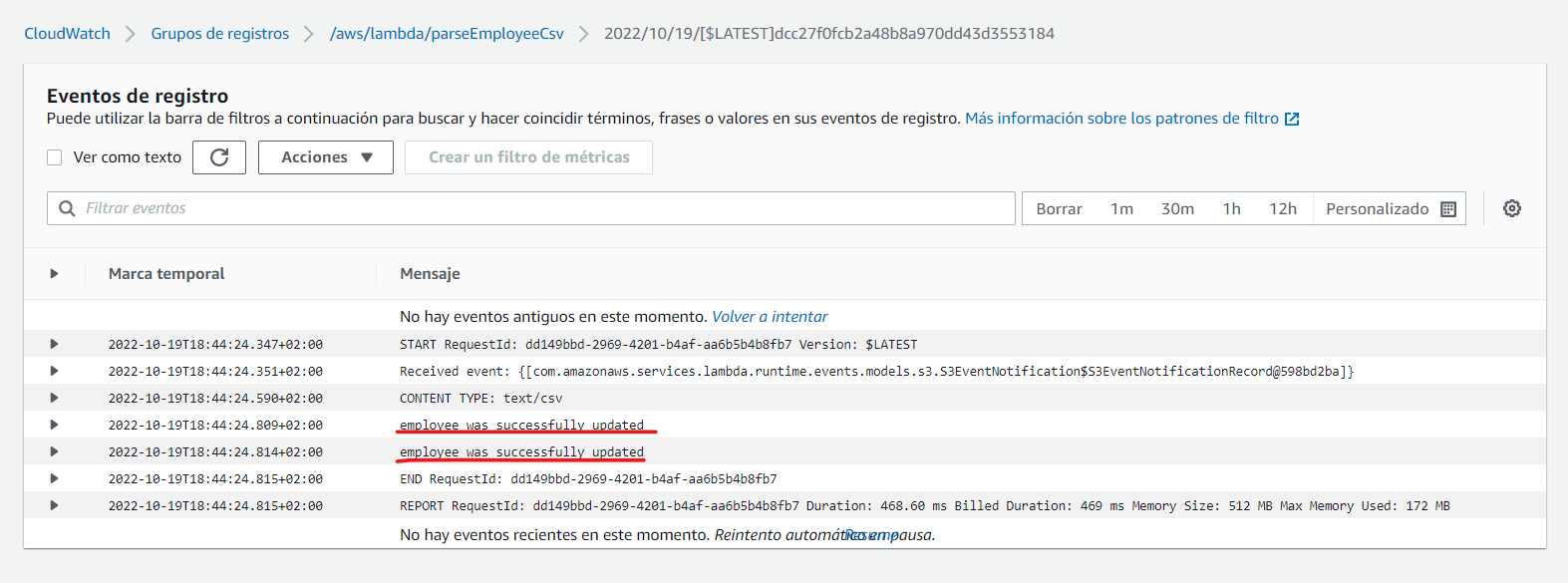
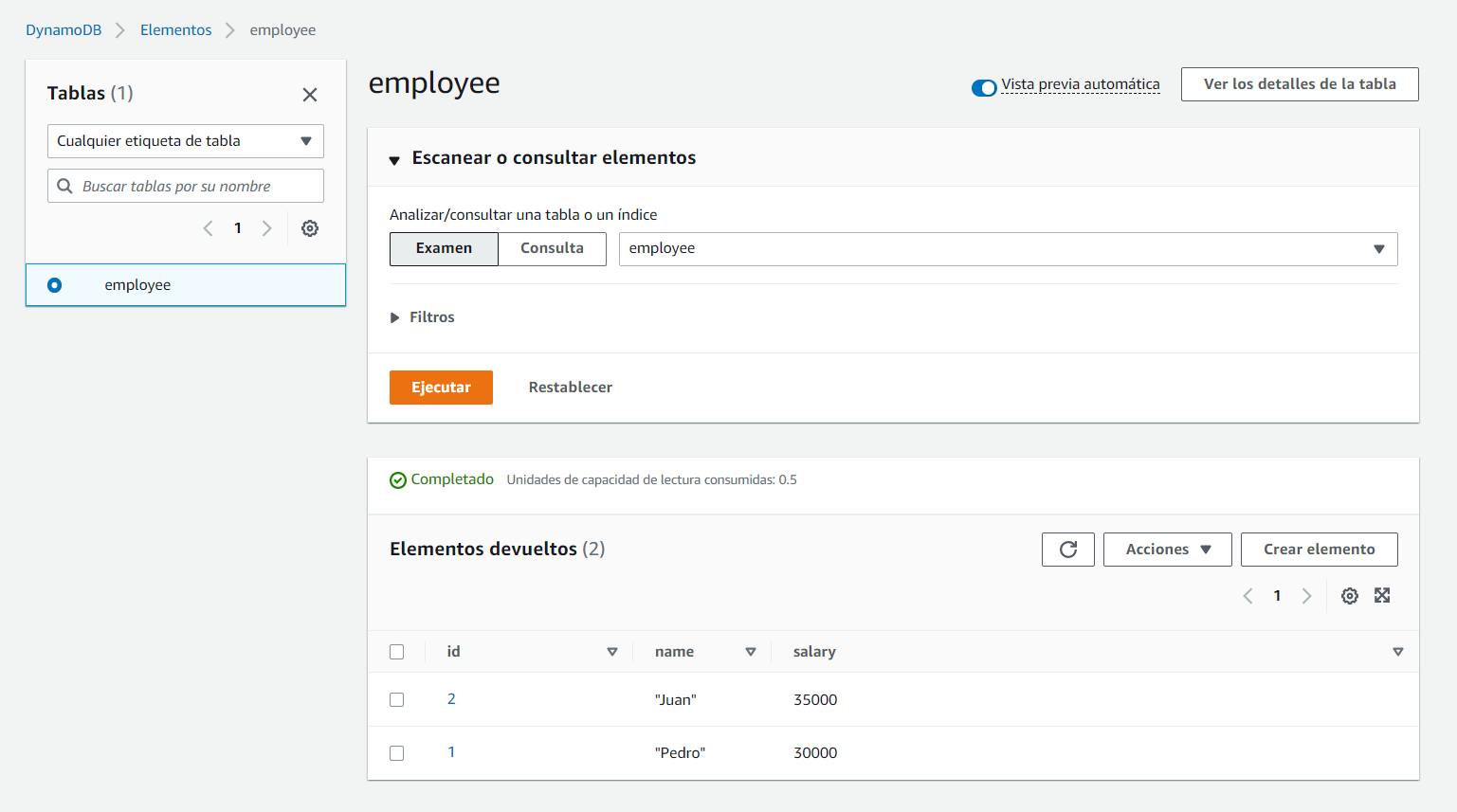
Por lo que, si nos vamos a la tabla “employee” del servicio DynamoDB, y exploramos sus elementos:
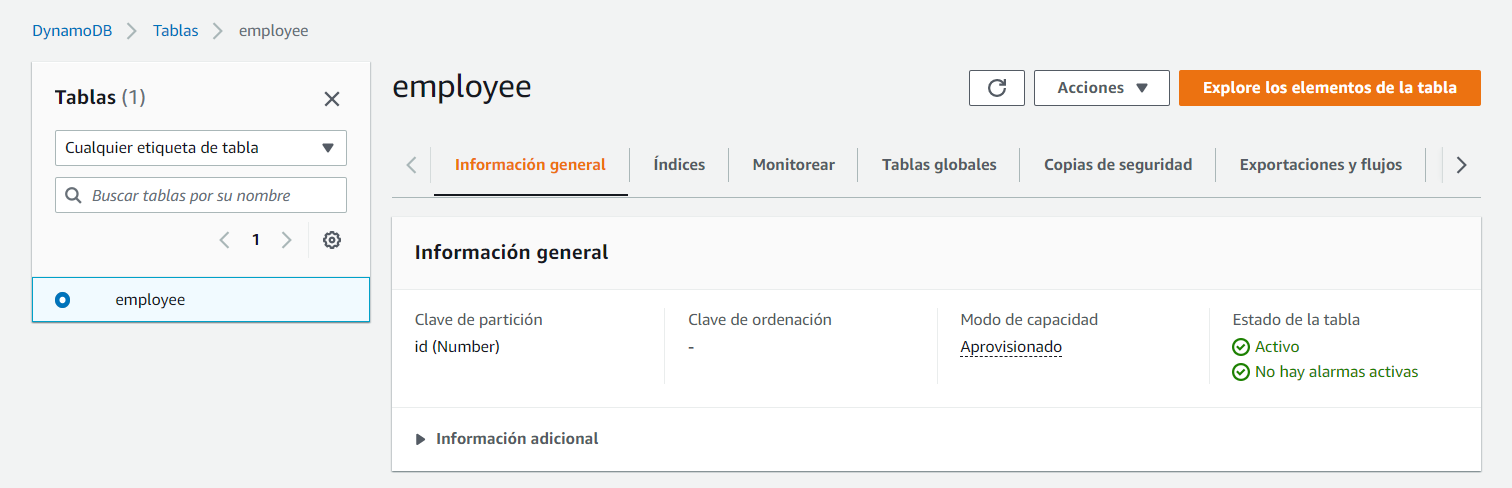
Veremos que hay 2 elementos, que se corresponden con los 2 empleados que existían en el fichero .csv:
Recursos
