Gestión de ficheros en AWS con Spring Boot
En muchas ocasiones, para llevar a cabo la lógica de negocio de una aplicación, se hace necesario trabajar con imágenes, documentos, ficheros de texto plano, etc., por lo que es vital un mecanismo resiliente y de alta disponibilidad para almacenar y recuperar esos archivos.
Amazon Simple Storage Service (Amazon S3) es un servicio ofrecido por AWS que nos brinda un almacenamiento de objetos escalable, seguro y de buen rendimiento.
Esta simple prueba de concepto nos va a permitir explorar las operaciones básicas de S3, como subir, eliminar y descargar ficheros del servicio de almacenamiento de Amazon AWS, todo ello integrado en una aplicación Spring Boot.
- Arquitectura de la solución
- Prerrequisitos
- Conceptos básicos de S3
- Creación del bucket en S3
- Crear usuario de acceso al bucket
- Creación del proyecto Spring Boot
- Creación de un bean de cliente de AmazonS3
- Creación del servicio de negocio.
- Tests
- Recursos
Arquitectura de la solución
La arquitectura de la solución es simple. Crearemos una aplicación Spring Boot, que contendrá un controlador REST para recibir las peticiones HTTP del cliente.

El negocio se desarrolla en un único servicio al que le hemos inyectado un cliente del servicio S3 que, haciendo uso del SDK de AWS para Java, permitirá conectar con él para realizar las siguientes operaciones:
- Subir un fichero a un bucket previamente creado
- Descargar un fichero existente en el bucket
- Eliminar un fichero existente en el bucket
- Listar todos los documentos existentes en el bucket
Prerrequisitos
- SDK Java 17
- Maven
- Cuenta en Amazon Web Services (AWS). Los primeros 12 meses son gratuitos, y el servicio S3 proporciona hasta 5 TB de almacenamiento gratuito.
- Tu IDE favorito. En este caso, Spring Tool Suite (STS)
Conceptos básicos de S3
Antes de comenzar, es interesante resaltar un par de conceptos básicos del servicio S3 de AWS, a modo de resumen, con el objetivo de facilitar la lectura de este artículo a los más nóveles.
Buckets
Los buckets son contenedores de objetos que queremos almacenar. Algo importante a tener en cuenta aquí es que S3 requiere que el nombre del bucket sea globalmente único.
Objetos
Los objetos son los documentos que estamos almacenando en los buckets de S3. Se identifican mediante una clave, que es una secuencia de caracteres Unicode cuya codificación UTF-8 tiene una longitud máxima de 1.024 bytes.
Delimitador de clave
Por defecto, el carácter “/” recibe un tratamiento especial si se utiliza en una clave de objeto. Un almacén de objetos no utiliza directorios ni carpetas, sino sólo claves. Sin embargo, si usamos un “/” en nuestra clave de objeto, la consola de AWS S3 renderizará el objeto como si estuviera en una carpeta.
Así, si nuestro objeto tiene la clave “foo/bar/test.json” la consola mostrará una “carpeta” foo que contiene una carpeta “bar” que contiene el objeto real “test.json”. Este delimitador de clave nos ayuda a agrupar nuestros datos en jerarquías lógicas.
Creación del bucket en S3
Crear un bucket en Amazon S3 a través de la consola de AWS es muy sencillo. Para ello, lo mejor es seguir la propia documentación del servicio, ya que es muy clara y siempre está actualizada: https://aws.amazon.com/es/getting-started/hands-on/backup-files-to-amazon-s3/
En este caso, vamos a crear un bucket con el nombre spring-boot-aws-s3-poc, seleccionando la región donde queremos que se despliegue y dejando por defecto el resto de configuración:

Una cosa a tener en cuenta es que el nombre del bucket debe ser único en todo AWS, no sólo en la cuenta usada.
Crear usuario de acceso al bucket
El primer paso es crear las credenciales de seguridad que se utilizarán para acceder a los servicios de AWS. Para ello, buscamos el servicio IAM, y accedemos a él para administrar el acceso a los recursos de AWS:

En el apartado de Usuarios, agregamos un nuevo usuario:

Asignamos un nombre al usuario y marcamos el check “Clave de acceso: acceso mediante programación”:

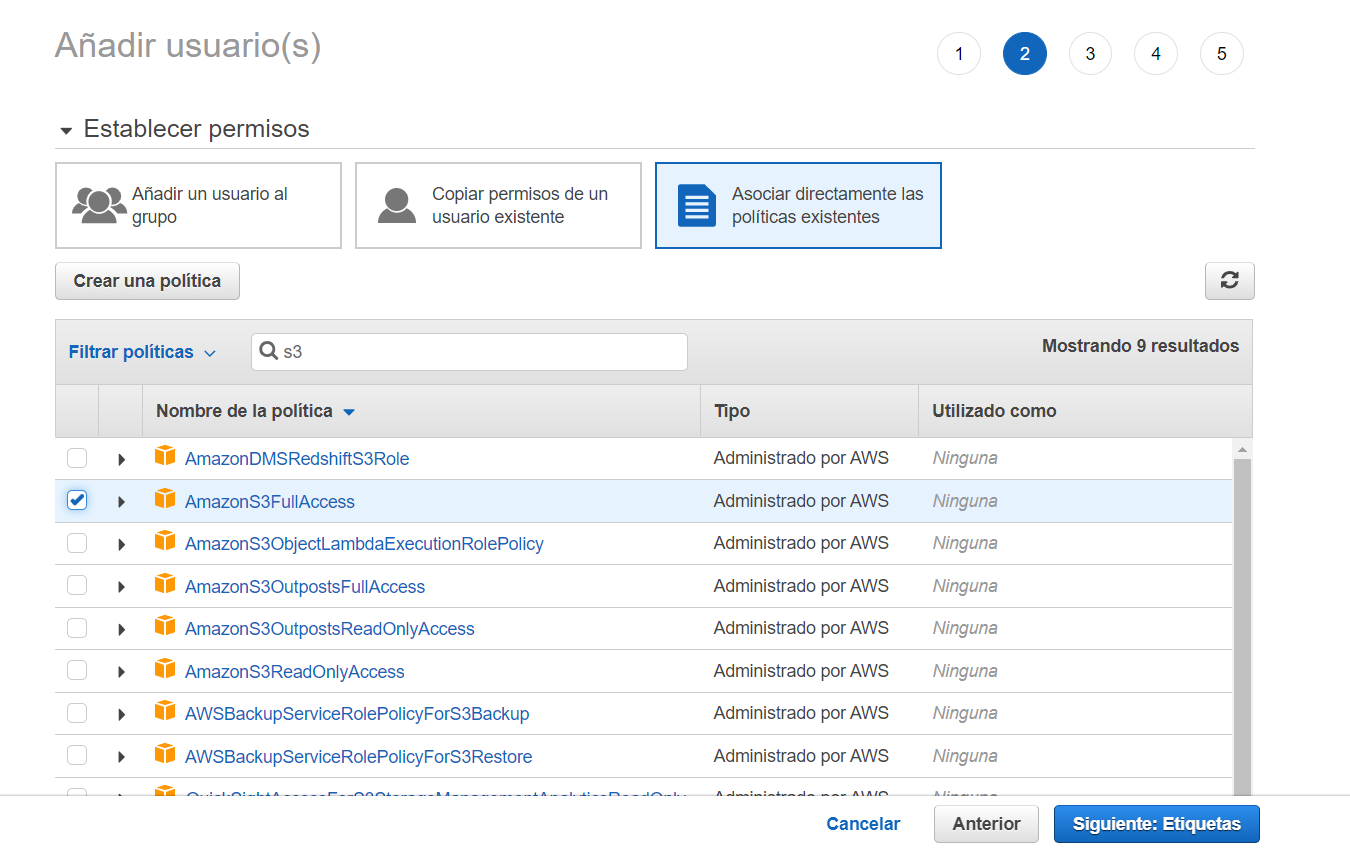
Avanzamos en el proceso hasta la sección de permisos, donde asignaremos al usuario la política AmazonS3FullAccess, lo que permitirá tener acceso completo al servicio Amazon S3:
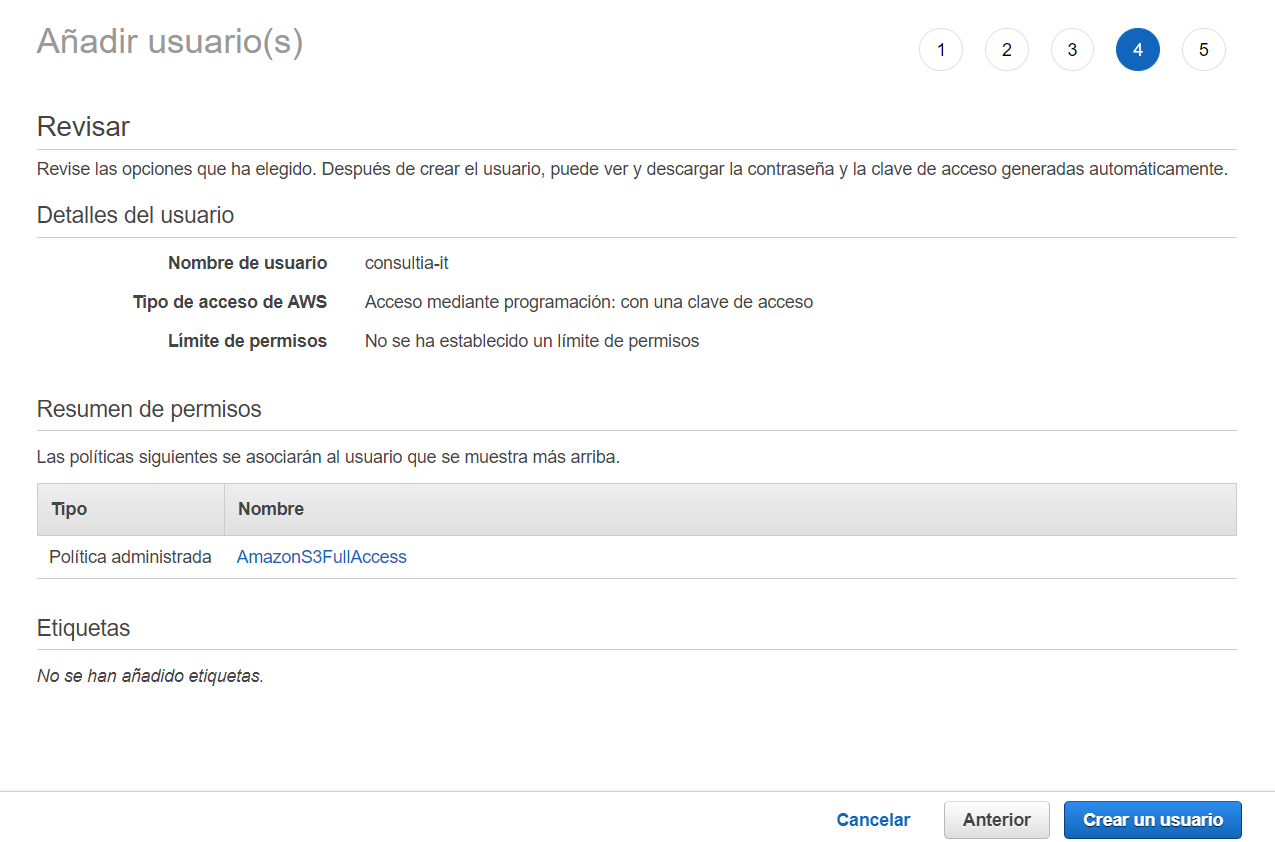
Avanzamos en los siguientes pasos hasta completar la creación del usuario:
Una vez creado el usuario, se nos presentan tanto la clave de acceso como el secret asignados. Es importante guardar estas claves ahora, ya que no estarán accesibles posteriormente, obligándonos a generar nuevas.

Creación del proyecto Spring Boot
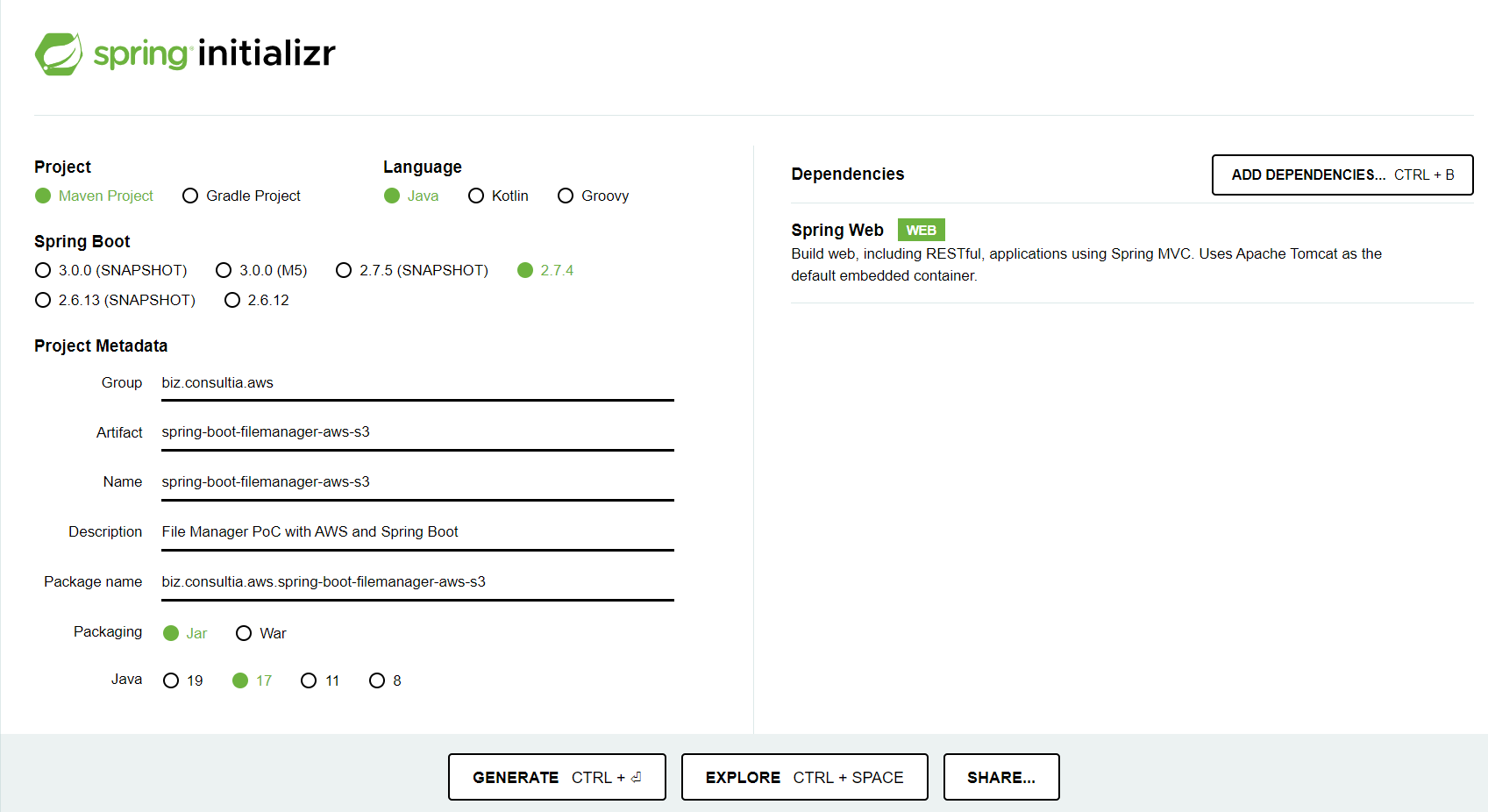
Haciendo uso de Spring Initializr, vamos a crear nuevo proyecto Spring Boot Java, con la dependencia Spring Web:
Una vez generado, lo importamos como proyecto Maven en Eclipse (o Spring Tool Suite, o tu IDE favorito).
Spring Cloud proporciona una forma cómoda de interactuar con el servicio S3 de AWS. Con la ayuda del soporte de S3 de Spring Cloud podemos utilizar todas las características conocidas de Spring Boot. También ofrece múltiples características útiles en comparación con el SDK proporcionado por AWS.
Para utilizar el soporte de S3 sólo tenemos que añadir la siguiente dependencia:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-aws</artifactId>
</dependency>
Lo siguiente es proporcionar las credenciales de AWS y las configuraciones del SDK, en el fichero de configuración application.yml:
## application.yml
document:
bucket-name: spring-boot-aws-s3-poc
cloud:
aws:
region:
static: eu-west-3
auto: false
credentials:
access-key: AKIAUND4E7ESIOKUCP3J
secret-key: your-secret
El fragmento de configuración anterior hace los siguiente:
region.static: establece estáticamente la región AWS como eu-central-1 (puedes elegir la más cercana a tí).stack.auto: esta opción permite la detección automática del nombre de la pila de la aplicación. Como no dependemos del servicio AWS CloudFormation en esta ocasión, se desactiva esa configuración.credentials.access-keyycredentials.secret-key: para establecer las credenciales de acceso a AWS.
Nota: En el inicio de la aplicación, es posible que veamos una excepción relacionada con Metadata o RegistryFactoryBean. En este caso, es necesario excluir cierta configuración automática en el fichero application.yml:
spring:
autoconfigure:
exclude:
- org.springframework.cloud.aws.autoconfigure.context.ContextInstanceDataAutoConfiguration
- org.springframework.cloud.aws.autoconfigure.context.ContextStackAutoConfiguration
- org.springframework.cloud.aws.autoconfigure.context.ContextRegionProviderAutoConfiguration
Creación de un bean de cliente de AmazonS3
Vamos a crear un cliente de AmazonS3 como un bean, que podremos inyectar en el servicio de documentos y nos permitirá realizar diferentes operaciones en el servicio AWS S3:
@Configuration
public class AwsS3Configuration {
@Value("${cloud.aws.credentials.access-key}")
private String awsAccessKey;
@Value("${cloud.aws.credentials.secret-key}")
private String awsSecretKey;
@Value("${cloud.aws.region.static}")
private String region;
@Primary
@Bean
public AmazonS3 amazonS3Client() {
return AmazonS3ClientBuilder
.standard()
.withRegion(region)
.withCredentials(new AWSStaticCredentialsProvider(
new BasicAWSCredentials(awsAccessKey, awsSecretKey)))
.build();
}
}
Para la creación del cliente se hace uso de un builder que proporciona el SDK (AmazonS3ClientBuilder), al que proporcionamos la configuración de la región y las credenciales que tenemos en el application.yml.
Creación del servicio de negocio.
En este único servicio de la aplicación se centralizará toda la lógica de negocio. Para poder llevarla a cabo, hará uso del cliente de S3 creado en el paso anterior:
@Service
public class AwsS3DocumentService {
@Value("${document.bucket-name}")
private String bucketName;
@Autowired
private AmazonS3Client amazonS3Client;
...
También se le inyecta el nombre del bucket que hemos indicado en el fichero de configuración.
Con esto, el servicio tiene todo lo necesario para implementar el acceso a los documentos en el servicio de almacenamiento de Amazon AWS, que veremos a continuación.
Subir un fichero al bucket S3
El cliente de Amazon S3 que generamos anteriormente proporciona múltiples métodos sobrecargados para subir distintos tipos de objetos como File, String, InputStream, etc.
En esta ocasión, vamos a utilizar el método putObject en nuestro bean cliente para subir un objeto al bucket de S3, en este caso de tipo MultipartFile:
/**
* Upload the given multipart file to the S3 bucket
* @param file the given multipart file to be uploaded to the S3 bucket
* @return the public URL of the uploaded file
*/
public String uploadFile(MultipartFile file) {
String filenameExtension = StringUtils.getFilenameExtension(file.getOriginalFilename());
String key = UUID.randomUUID().toString() + "." + filenameExtension;
ObjectMetadata metaData = new ObjectMetadata();
metaData.setContentLength(file.getSize());
metaData.setContentType(file.getContentType());
try {
var putObjectRequest = new PutObjectRequest(bucketName, key, file.getInputStream(), metaData)
.withCannedAcl(CannedAccessControlList.PublicRead);
amazonS3Client.putObject(putObjectRequest);
}
catch (AmazonServiceException e) {
// The call was transmitted successfully, but Amazon S3 couldn't process it, so it returned an error response.
e.printStackTrace();
}
catch (SdkClientException e) {
// Amazon S3 couldn't be contacted for a response, or the client couldn't parse the response from Amazon S3.
e.printStackTrace();
}
catch (IOException e) {
throw new ResponseStatusException(HttpStatus.INTERNAL_SERVER_ERROR, "An exception occured while uploading the file");
}
return amazonS3Client.getResourceUrl(bucketName, key);
}
Especial atención, durante la creación del objeto PutObjectRequest, a la definición de la política de control de acceso que aplicará para el documento que se va a cargar en el bucket:
new PutObjectRequest(bucketName, key, file.getInputStream(), metaData)
.withCannedAcl(CannedAccessControlList.PublicRead); <================
Con esto, lo que estamos diciendo es que cualquiera podrá acceder a este objeto de manera pública.
Descargar un fichero desde el bucket de S3
Podemos utilizar el método getObject en nuestro bean cliente de AmazonS3 para obtener un objeto del bucket de S3 a partir de su clave.
El método getObject devuelve un S3Object, que podemos convertir en un array de bytes:
/**
* Gets the bytearray of the file with the given key stored in the S3 bucket
* @param key the key under which the desired object is stored
* @return the byte array of the file
* @throws IOException
*/
public byte[] getFile(String key) throws IOException {
S3Object data = amazonS3Client.getObject(bucketName, key);
S3ObjectInputStream objectContent = data.getObjectContent();
byte[] bytes = IOUtils.toByteArray(objectContent);
objectContent.close();
return bytes;
}
Eliminación de un objeto del bucket de S3
Podemos utilizar el método deleteObject en nuestro bean cliente de AmazonS3 para eliminar un objeto del bucket a partir de su nombre:
/**
* Deletes the document with the given file name from the S3 bucket
* @param fileName the name of the file to be deleted from the S3 bucket
*/
public void deleteDocument(String fileName) {
amazonS3Client.deleteObject(bucketName, fileName);
}
Tests
A continuación, vamos a probar nuestra aplicación Spring Boot. Para ello, con la aplicación levantada, haremos una serie de peticiones REST haciendo uso de Postman:
1. Subida de un fichero al bucket S3
POST http://localhost:8080/documents
El endpoint que atacamos aquí es POST /documents, con el fichero contenido en el body de la petición (de tipo form-data).

Una vez ejecutada la petición, el endpoint devuelve la URL pública de acceso al fichero recientemente cargado en el bucket de S3.
Podemos comprobar que el fichero se ha cargado correctamente desde la consola de AWS:
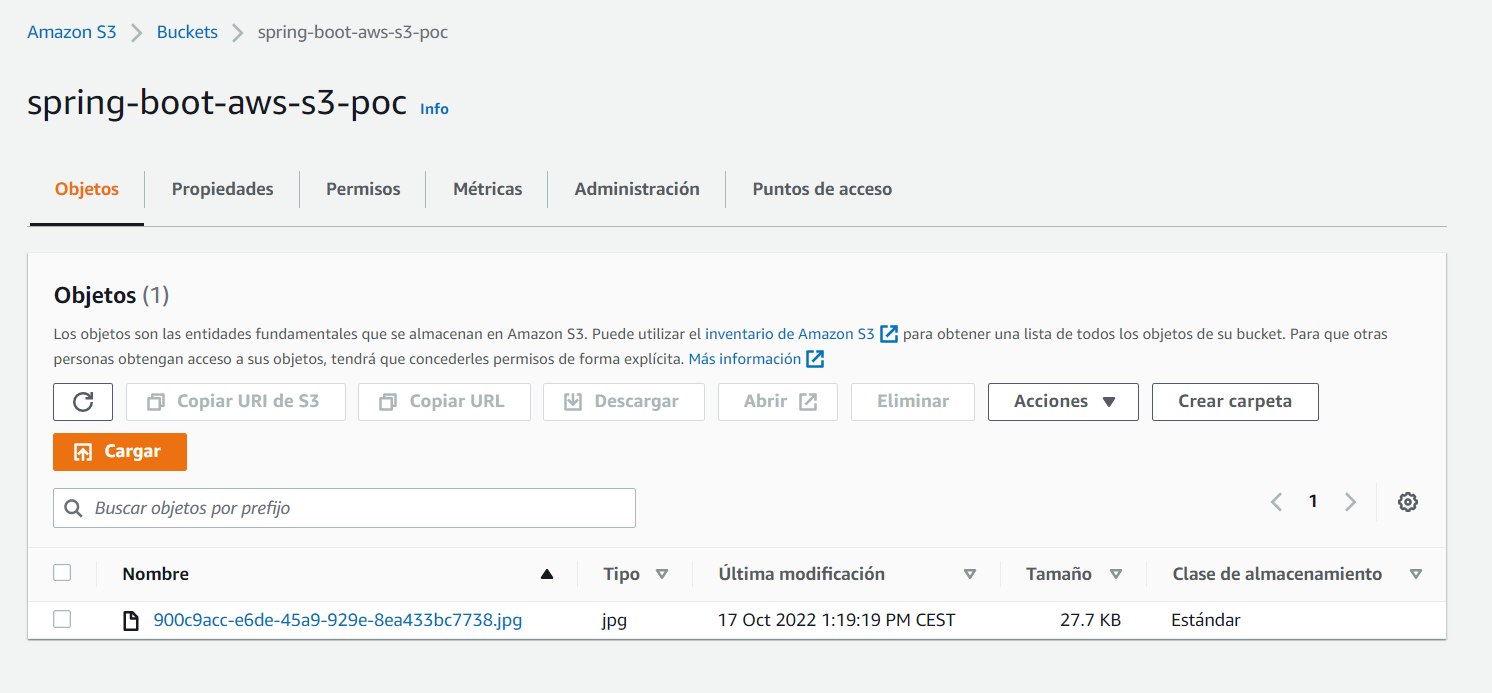
2. Lectura de todos los ficheros subidos actualmente en el bucket
GET http://localhost:8080/documents
Atacando al endpoint GET /documents, obtenemos la clave (key) de todos los ficheros que contiene el bucket. En este caso, sólo uno, que se corresponde con el fichero subido en el paso anterior.

3. Descarga del fichero
GET http://localhost:8080/documents/900c9acc-e6de-45a9-929e-8ea433bc7738.jpg

4. Borrado del fichero
DELETE http://localhost:8080/documents/900c9acc-e6de-45a9-929e-8ea433bc7738.jpg

5. Comprobamos que el fichero ha sido eliminado
GET http://localhost:8080/documents

Como podemos comprobar, la respuesta es un array vacío, que indica que no hay ningún documento en el bucket tras eliminar el único fichero que existía en el paso anterior.
Recursos
